 The main
file menu offers the choice of ANSI or Unicode encoding. This affects
the way strings are stored in LMP files, and nearly doubles the file size
when Unicode is selected.
The main
file menu offers the choice of ANSI or Unicode encoding. This affects
the way strings are stored in LMP files, and nearly doubles the file size
when Unicode is selected.Visual Basic Version 6 (and earlier) does not support Unicode in the external interface. VB stores strings internally using Unicode, but assumes that the outside world is ANSI. This didn't used to be much of an issue because Unicode was pretty esoteric stuff, not supported at all in Win9x and not supported thoroughly in NT. Since almost nobody in the Windows/VB world was using Unicode, I seldom heard from VBLM users trying and failing to use Unicode while localizing their VB apps.
This changed shortly after the release of Windows 2000, because not only did W2K fully support Unicode, but it also shipped with support for all languages, Asian languages included. I suddenly had many customers calling up and wondering, since they could easily display, say Chinese characters, on their English W2K machines, why did they only get "???" when they pasted the Chinese strings into VBLM. I've spent a lot of time since explaining to people that almost all VB controls don't work with Unicode fonts and hence can't properly display Unicode strings. My advice has always been to forget about Unicode and use Microsoft's proprietary DBCS (double byte character set) fonts instead. Note that the encoding schemes are completely different: the bytes that represent a given Chinese string in Unicode are entirely different from the bytes that represent the same string in DBCS.
I was within a week of releasing VBLM V6 when I got an e-mail from longtime customer, beta tester, and localization expert Michiel de Bruijn. In it, he complained that he was having trouble importing Unicode LMX files into VBLM. Huh?? Michiel knows more about VB and Unicode than I ever will, so instead of sending back my usual "forget about Unicode, it doesn't work" response, I replied that I had always thought that it didn't work, and what was he getting at? Our correspondence is reproduced in full at the end of this topic, but to summarize:
1) VB stores strings internally as Unicode, but the trick is getting them in and out. Since VB assumes the world is ANSI, it converts from ANSI on the way in, and to ANSI on the way out. If the string coming in is already Unicode, the conversion corrupts it. If you want the string coming out to stay Unicode, tough luck (I already knew this).
2) This problem can be overcome by using the byte datatype instead of strings. When you convert strings into arrays of bytes, VB does not convert them (I knew this too).
3) VB apps always use the system codepage (ie the regional/locale setting) when they convert between internal Unicode and external ANSI. I didn't know this, or at least I didn't appreciate the implication of it, which is:
4) If you can get the correct Unicode strings in and out of VBLM (which is a VB app), and if you run VBLM on the correct regional version of Windows (ie, one with the same system codepage as the target language), when VBLM builds the localized version it will correctly convert the Unicode strings to DBCS strings as it writes the files and everything will work just fine.
I thought that this was so potentially useful (not to mention the bragging rights that come with Unicode support) that I delayed the release of V6 to write and test the code needed for implementation. Thus when VBLM V6+ is started with the /Unicode switch on its command line, or (new in V6.01) if you have checked Enable Unicode Encoding on the Help Etc tab of the general options window:
The main
file menu offers the choice of ANSI or Unicode encoding. This affects
the way strings are stored in LMP files, and nearly doubles the file size
when Unicode is selected.
The export
options window offers the choice of creating Unicode LMX files
The import options window indicates
the encoding scheme of the file about to be imported, and correctly imports
Unicode files.
The language
database format setting lets you create Unicode resource files (Unicode
support for the other LDB formats will come later, as they require that
I write many more RSV support files and add Unicode to the selection logic).
These options allow you to use Unicode with VBLM as described above, but there are some things to keep in mind:
1) If you do your development work on machines running Win9X, forget about Unicode. You must run NT, W2K, or XP for this to work. Since a) a fair number of VBLM users run Win9x, and b) a fair number of VBLM users are less than scrupulous about RTFM, I created the /Unicode switch to enable these capabilities only after the user has read enough of the docs to stay out of trouble. However, as of V6.01, you can skip the /UNI switch and enable Unicode on the Help Etc tab of the general options window. It will not activate, however, until you restart VBLM.
2) You will still need DBCS fonts for the localized VB apps. They are needed to properly display the DBCS bytes converted from Unicode.
3) The Unicode strings are still going to display as "???" in VBLM unless it is running on the matching regional version of Windows. If you export them with Unicode encoding, load the LMX file into Notepad and select an appropriate font, however, you'll see that all the right bytes are there:
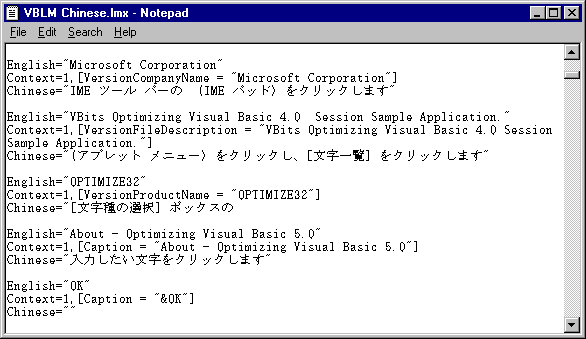
(The Chinese characters shown are random cut and paste, not correct translations)
The correspondence in which Michiel explains things better than I can:
===================================================================
From: michiel de bruijn
To: Ben Whipple
Date: Thursday, March 21, 2002 10:54 PM
Subject: VBLM 6 and Unicode
Hi Ben,
I just started to enter some Korean translations into VBLM6, and am encountering some problems.
I started out by exporting a LMX file on my own system (regular US English w/Dutch locale), and editing the LMX on a machine with Korean Windows 2000 installed. The thus newly created Unicode version of the LMX imported fine on my system, and the LTE showed an "ANSI-ized" version of the Korean characters, which is usually a good sign, since all the bytes are there.
I then proceeded to build my project, but upon executing the EXE, all strings still showed up "ANSI-ized". I figured this was because of the way the resource strings are loaded, and tried a few modifications to VBLM_RTString. Specifically, I changed LoadResString(lCurrentOffset + Index) to LoadResData(lCurrentOffset + Index, 6), then converted the byte array to a string with StrConv. But no matter which conversion type I used (vbUnicode, vbFromUnicode, vbWide, vbNarrow), the effect was the same: "ANSI-ized" text when running the EXE.
As I'm not sure how VBLM handles translated strings internally, and what happens in the realm of Unicode/ANSI conversion when you write them to the resource file, I gave up on this particular approach for the time being.
Next, I ran VBLM from the Korean machine and tried to enter the translations manually into the LTE. This wasn't too successful either, as VBLM truncates each translation to half its actual width as soon as I press Enter (most likely because you rely on VB's Len() to behave sensibly, which it really doesn't in a native double-byte Unicode environment). Again, I'm not sure of the internal data structures you use to hold the translations, so I can't really comment on the best way to fix this. Another anomaly was that VBLM got really unhappy importing the Korean LMX on the Korean platform.
I'm pretty sure that I successfully used Unicode LMX files with previous versions of VBLM (running on a US English system, using the proprietary file format), and I think that my current problems with that approach have to do with the way translations are written to the RC file. Depending on how exactly you write the translations to the RC file (what is the native data type, who/what does the Unicode conversion, which output method [VB/API?] is used), there may be a trivial fix for the issue I'm seeing, in adding a 'translations are Unicode' flag to the language table (or even auto-detecting this fact) and doing the Unicode conversion slightly differently in that case (e.g. not doing a conversion at all).
Anyway, please let me know if I'm making any sense so far, and if you need any more specific feedback from me about what I'm trying to do and/or what I think the problem is. If the latter, it would be most helpful to know the data type of the variables that VBLM keeps the translations in, as well as the methods you use for file I/O.
'//mdb
===================================================================
From: Ben Whipple
To: michiel de bruijn
Date: Friday, March 22, 2002 9:39 AM
Subject: Re: VBLM 6 and Unicode
Hi:
To the best of my knowledge, neither VB nor VBLM has ever supported Unicode. I could fiddle around with the internal processing, but VB is never going to display them as anything other than ???
Am I wrong about this?
Ben
===================================================================
From: michiel de bruijn
To: Ben Whipple
Date: Friday, March 22, 2002 1:35 PM
Subject: Re: VBLM 6 and Unicode
Hi Ben,
The internal string format for VB (and any app written in it) is Unicode, and I've used VBLM successfully in the past to localize apps into Simplified Chinese and Traditional Chinese, both using Unicode character sets.
A little background: when VB4 was developed, it was all based on COM (then still called OLE...), which stores all variable-length strings (BSTRs) in Unicode. However, since Windows 95 was still Microsoft's flagship operating system, and that platform had only very limited support for Unicode, the VB developers had to put in a bit of a hack: whenever strings left VB (like when being written to a file or passed to an API call), they are converted to ANSI, using the locale rules of the system the app is running on.
The most important side-effect of this hack was that VB developers could no longer store binary data in strings, which had been *the* way to do it in previous versions. To see why, consider reading a 3-byte file consisting of (1)(2)(3) into a string variable using the Get statement.
The resulting string is stored in memory as (1)(0)(2)(0)(3)(0) on Windows versions using the US English locale. However, on systems using a natively multibyte locale, such as most Asian versions of Windows, (2)(3) may be a valid DBCS character. In this case, the in-memory representation of our test string will become something like (1)(0)(147)(148), where (147)(148) is the Unicode representation of the DBCS tuple (2)(3). This corrupts the binary data, and makes it come up one byte short when read back -- during the VB4 beta, this quickly became known as 'Unimess'.
To solve this problem, Microsoft introduced the Byte data type in VB4. This would have been a good solution, if it weren't for the fact that they 'forgot' to implement any decent operators that work on it: Instr, Left, Mid, Right, etc. all won't work with Bytes, making may programmers stick with Strings for binary data anyway. After all, their programs worked fine on their own machines... (but crash and burn badly on Asian/Middle East machines). Despite many, many requests by developers, this was never rectified in VB5 or 6. Fortunately, VB.NET does have a decent set of binary operators.
Back to VBLM. I'm assuming for the moment that you store the translations in Strings internally, which means they'll work with Unicode quite well, even if the LTE interface doesn't support the particular code page or allows editing of these strings. Here's how it would work:
1. Create an empty language table and export it to a LMX file. This LMX file will be ANSI
2. Take the LMX file to a system running the target locale OS (which must be NT/2000/XP, 9x won't do the trick due to their halfhearted Unicode implementation), and edit the LMX file using Notepad, or another Unicode-aware editor.
3. The LMX file will now turn into Unicode -- basically, it will get twice as big and gain some bytes in the front (the Unicode signature)
4. When VBLM uses Open For Input on the LMX file, VB will recognize the Unicode signature and do the right thing, i.e. not do any string conversion
5. At the end of the import, all the strings in the language table will be valid Unicode strings
Now, note that the strings won't:
-display correctly in the LTE (it doesn't use the right code page, so you'll just see ???'s or other garbage)
-editing and/or exporting them will corrupt them (editing seems to incorrectly rely on Len() to return the length of the string in bytes, exporting will do Unicode-to-ANSI conversion the wrong way)
...but building a project should just work fine, as long as you use normal VB statements to handle the strings.
When using a RC/RES file, though, things break down for the same reason LTE exports don't work. Because VB does Unicode-to-ANSI conversion when writing the (ANSI) RC file, followed by RC.EXE doing its own ANSI-to-Unicode conversion, the Unicode strings become ANSI-ized, even though all the bits are still there. Consider the Unicode strings (1)(0)(2)(0) [English] and (1)(2)(3)(4) [Asian] in VB. When writing the RC file, VB will, based on the LCID 1033 conversion rules, write (1)(2) and (1)(2)(3)(4) to the RC file. RC.EXE will output (1)(0)(2)(0) and (1)(0)(2)(0)(3)(0)(4)(0) to the Unicode RES file.
The solution, from a VBLM perspective, is easy -- write a Unicode .RC file:
Dim bUnicodeSignature(1 To 2) As Byte, bResString() As Byte, ResString As String
If Len(Dir$("c:\tmp\sample.rc"))
Then Kill "c:\tmp\sample.rc"
Open "c:\tmp\sample.rc" For Binary As #1
bUnicodeSignature(1) = &HFF: bUnicodeSignature(2)
= &HFE
Put #1, 1, bUnicodeSignature
ResString = "STRINGTABLE DISCARDABLE"
bResString = ResString
Put #1, , bResString
Close #1
The resulting sample.rc will look normal in Notepad (at least, on NT/2000/XP), but if you open it using a hex editor, you'll see it's actually a Unicode file. Although you can safely write a Unicode RC file, even if only ANSI strings are involved (RC.EXE will convert ANSI strings to Unicode anyway...), Win9x VBLM users may be less than thrilled with Unicode RC files, so creating these should probably an option.
As for making VBLM's LTE Unicode-safe, there's two things to this:
1. (trivial) Export Unicode LMX files in the same way as RC files
2. When editing a string, do not assume Len() returns the number of bytes in the string.
Depending on the exact processing you do on a translation string once the user hits Enter in the LTE, the fix may be quite trivial, or close-to-impossible. But I would be very, very happy if VBLM could at least write Unicode RC and LMX files, and I think this would satisfy the needs of most other developers targeting 'wide' Unicode locales as well -- the LTE changes are only required to make VBLM work 100% correctly on, say, Korean systems.
'//mdb
=====================================================================
From: Ben Whipple
To: michiel de bruijn
Date: Monday, March 25, 2002 9:46 AM
Subject: Re: VBLM
6 and Unicode
Hi Michiel:
Thank you VERY much for taking the time to lay out the Unimess issue so cogently. I knew much of this, but in dribs and drabs and not in a coherent whole. I did a little experimentation over the weekend. For various reasons, Unicode LMX files will be a lot of work, and I doubt that they will make it into V6 -- V6.1, more likely. However, I think the Unicode res files are doable, and will experiment further today.
BTW, one thing I still don't understand. Most VB controls don't accept Unicode, correct? So are you saying that VB will correctly convert a Unicode string into a matching DBCS code? VB apps can only work with the system code page, so the correct conversion occurs on systems with the appropriate one set? Otherwise, I still don't understand the value of using strings that can't be displayed as part of the visible interface.
A little knowledge here is dangerous, as I struggle to explain Unicode difficulties to customers all of the time -- ever since W2K let people easily display Asian characters on English systems, I get a steady stream of inquiries.
Ben
=====================================================================
From: michiel de bruijn
To: Ben
Whipple
Date: Monday,
March 25, 2002 12:43 PM
Subject: Re:
VBLM 6 and
Unicode
Hi Ben,
>I did a little experimentation over the weekend. For various reasons, Unicode LMX files will be a lot of work, and I doubt that they will make it into V6 -- V6.1, more likely. However, I think the Unicode res files are doable, and will experiment further today.
OK, the LMX files wouldn't be too bad, especially since they can be converted into the right format pretty easily outside of VBLM -- it's a kludge, but it will work. Having Unicode RES files would be fantastic, though, as it would allow me to start doing Korean and Chinese builds without switching to a non-RES language file format.
>BTW, one thing I still don't understand. Most VB controls don't accept Unicode, correct?
Correct. You can pretty easily get drop-in Unicode replacements for most built-in VB controls, though: Tools/Components, Microsoft Form Package 2.0. After you search/replace the control class names in your FRM file, you're pretty much set. It's a hack, but it'll work. Third-party controls from sane large vendors (i.e. not Infragistics) are also seeing more and more Unicode support.
>So are you saying that VB will correctly convert a Unicode string into a matching DBCS code? VB apps can only work with the system code page, so the correct conversion occurs on systems with the appropriate one set?
Yes, this is exactly what happens. If I assign Thai Unicode strings to standard VB controls while running on the US platform, I get garbage. When running on a Thai version of Windows, though, all is fine. There will always be a few Unicode code points that don't map to the right DBCS tuple (copyright and trademark signs are the most likely victims here, but for them there's always the fully Unicode-enabled Picture.Print...), but you can work around that quite easily in most apps and most languages. I know there are some languages for which this doesn't work at all, but I've never personally encountered them so far -- in these situations you would need full Unicode controls, though.
>A little knowledge here is dangerous, as I struggle to explain Unicode difficulties to customers all of the time -- ever since W2K let people easily display Asian characters on English systems, I get a steady stream of inquiries.
Depending on what the final Unicode-related feature set of VBLM 6 will be, it would not be too much trouble for me to write up a help topic that describes how to do Unicode localization, describing the current possibilities and limitations. Also, if you see a chance of replacing the LTE controls with fully Unicode-aware versions for a future release, you'lll actually have all the pieces to do a reasonable job of allowing localization using any code page supported by Windows, regardless of the OS LCID. The only thing that will always be tricky is keyboard entry for non-OS-native locales[1], but for most users this will be a non-issue, as actual localization will take place on systems with the proper native locale anyway. '//mdb
[1] This is because Windows depends on the thread LCID to determine which Input Method Editor [IME] should be used, and VB always sets the thread LCID to the system LCID. So even if you have a Unicode text box with, say, Korean text, and your US copy of Windows has the right code page and IME installed, the text will display correctly, but the required IME will not be available for input, limiting you to regular ANSI text input. You could use SetThreadLocale to fix this problem to some extent, but it has been a while since I last attempted this, and I seem to recall there are all kinds of issues with this.
=====================================================================
From: Ben Whipple
To: michiel de bruijn
Date: Wednesday, March 27, 2002 12:11
PM
Subject: Unicode
Hi:
I've spent the last few days in VBLM's guts, adding Unicode capabilities, and just uploaded Build 125.
1) to have VBLM save Unicode strings in the LMP file, click Encoding Method on the main file menu, and select Unicode.
2) to have VBLM create Unicode LMX files, check the Unicode Encoding box on the Export window.
3) to have VBLM create Unicode resource files, check the Unicode Encoding box on the LDB format page of the build window.
I'm not implementing Unicode for the other LDB formats right now, because I will need to create 27 more support files.
I'd appreciate it if you could test these features ASAP and let me know if they work properly and do what you need and expect.
Also, I'd be absolutely thrilled to accept your offer to provide a discussion of Unicode issues as they relate to VB and VBLM.
Also, I'm going to look into a Unicode-enabled text box -- that's the only control I need to make the LTE work properly (all other display is ExtTextOut'd).
Ben
=====================================================================
From: michiel de bruijn
To: Ben Whipple
Date: Monday, April 01, 2002 10:39 PM
Subject: VBLM 6 & Unicode
Hi Ben,
Sorry for being a bit unresponsive for the past few days, but things have been a bit hectic around here.
Anyway, good news on the VBLM6 Unicode front: with the exception of Unicode LMX imports, all seems to be fine!
Here's what I did just now:
0. Open my project, set File/Encoding to Unicode (on a US Windows 2000 machine)
1. Create a Korean language table
2. Export as a Unicode LMX file
3. Edit LMX file with Notepad on Korean machine
4. Import LMX file on US machine
5. Noticed that Unicode strings got ANSI-ized: not good...
6. Ran VBLM on the Korean machine, entered translations directly into the LTE. Even though the strings get chopped in half upon leaving the edit control, they re-appear OK when I go back and edit them again
7. Saved project on Korean machine
8. Opened project on US machine, noticed strings show up as ???s in the LTE: good
9. Built project with Unicode RC file on US machine
10. Compiled project runs OK on Korean machine, displaying all translated strings correctly
I assume it's trivial to fix the LMX import behavior, at which point I (and lots of other customers, I guess) should be pretty happy. If you see a chance to fix the LTE edit behavior (if you want, I can send you some screenshots and more detailed explanation of what happens on a machine with a wide Unicode locale...), things would be just about perfect.
'//mdb
=====================================================================
From: Ben Whipple
To: michiel de bruijn
Date: Tuesday, April 02, 2002 10:38 AM
Subject: Re: VBLM 6 & Unicode
Hi:
>5. Noticed that Unicode strings got ANSI-ized: not good...
How do I avoid this?
I spent 3 days fooling around with it, and what ended up in the LMP file was inevitably different from what was in the LMX file. I thought you had said that VBLM would recognize the file as Unicode when it opened it, and hence would not convert the strings.
I assumed I could Line Input# them.
Do I need to get bytes instead?
>I assume it's trivial to fix the LMX import behavior, at which point I (and lots of other customers, I guess) should be pretty happy. If you see a chance to >fix the LTE edit >behavior (if you want, I can send you some screenshots and more detailed explanation of what happens on a machine with a wide Unicode locale...), things would be >just about perfect.
Yes, screenshots and details would be very helpful.
Ben
=====================================================================
From: michiel de bruijn
To: Ben Whipple
Date: Tuesday, April 02, 2002 12:43 PM
Subject: Re: VBLM 6 & Unicode
Hi Ben,
Hmm, I just checked, and it seems that Line Input is broken in VB6 in an interesting way -- it correcly opens the Unicode text file and retrieves the data, but then still munges the string for no apparent reason. I'm pretty sure that this used to work just fine in VB4, perhaps VB5, but it could be that working with .NET for more than a year has created some false memories :-)
Anyway, the easiest workaround is to use the Windows Scripting object to open Unicode files, as its syntax is very similar to VB's:
Dim fs As New FileSystemObject, tsIn As TextStream, tsOut As TextStream, lin As String
'//Format=TristateTrue means: this is a Unicode file
Set tsIn = fs.OpenTextFile("c:\dev\prism\korean.lmx",
ForReading, Format:=TristateTrue)
Set tsOut = fs.OpenTextFile("c:\tmp\test", ForWriting, Create:=True,
Format:=TristateTrue)
While Not tsIn.AtEndOfStream
lin = tsIn.ReadLine
tsOut.WriteLine lin
Wend
tsIn.Close
tsOut.Close
(this creates a valid copy of a Unicode text file)
The not-so-good part is that this requires a reference to the Microsoft Scripting Object, which some users *may* not have installed on their machine (I doubt any of them are developers, as IE5 will install it for you). You can redistribute it with VBLM, though: see http://www.microsoft.com/msdownload/vbscript/scripting.asp for version 5.5 (which is the last one to work on Win95) or MSDN for 5.6, which requires at least Windows 98 (like the rest of IE6). It's also possible to write a Line Input replacement, but there will be some complications with this approach if very long strings are present in the text files.
I've attached 3 screenshots of the LTE running on a Korean system. Here's what I did:
1. I open the multi-instance LTE for the string &Antivirus, and enter the Korean translation. This yields LTE1.JPG, which looks correct
2. I then move on to the next field: this yields LTE2.JPG, which cuts the translated string in half (it was 6 characters/12 bytes, now is 3 characters)
3. I enter the translation in the second field and move back to the first: this yields LTE3.JPG
4. The strings I input in the LTE this way show up correctly in the final VB project that VBLM builds.
So, in edit mode, all is OK, it's just that the display routine somehow only outputs half the required amount of bytes. Solving this issue might be as easy as using the following function instead of Len():
Function LenMbcs (ByVal str as String)
LenMbcs = LenB(StrConv(str, vbFromUnicode))
End Function
'//mdb
=====================================================================
From: Ben Whipple
To: michiel de bruijn
Date: Wednesday, April 03, 2002 12:15
PM
Subject: Re: VBLM 6 & Unicode
Hi:
Thanks for the info.
The scripting stuff is unlikely, but I will investigate.
Thanks
Ben
=====================================================================
From: Ben Whipple
To: michiel de bruijn
Date: Thursday, April 04, 2002 11:21 AM
Subject: Re: VBLM 6 & Unicode
Hi:
I have just uploaded Build 127.
Along with many other small changes:
1) to get at the Unicode stuff, you must start VBLM with /UNI on the command line. This is to prevent people who have no clue from hurting themselves and calling tech support to complain.
2) I believe that the width problem with Unicode display in the LTE is fixed, but would appreciate fast confirmation of this.
3) I believe that I've gotten around VB's corrruption on Unicode import by writing a replacement line input function. It seems to work very well, but I would also appreciate confirmation of this.
Thank you for your help.
Ben
=====================================================================
From: michiel de bruijn
To: Ben Whipple
Date: Friday, April 05, 2002 1:36 PM
Subject: Re: VBLM 6 & Unicode
Hi Ben,
After discovering the /UNI switch, I'm happy to report success on all counts, and I just did my first 'unaided' VBLM 6 Korean build from a LMX import! Attached is a screenshot of the LTE running on a Korean version of Windows 2000, showing all text correctly in both edit and display mode.
=====================================================================
From: Ben Whipple
To: michiel de bruijn
Date: Friday, April 05, 2002 3:58 PM
Subject: Re: VBLM 6 & Unicode
Hooray!
BTW, you do need a DBCS Korean font to do this, correct?
=====================================================================
From: michiel de bruijn
To: Ben Whipple
Date: Friday, April 05, 2002 5:33 PM
Subject: Re: VBLM 6 & Unicode
Hi Ben,
Yup, that, plus a system with the right system LCID, as VB always does its wide-to-narrow conversion using that code page. So even if you have your US system all set up with the right Korean fonts etc., you'll still only see question marks there. One way to fix this is to play around with SetThreadLocaleID, but getting this right will take some time.
=====================================================================